Cameron O'Rourke
오라클 테크놀러지스트
애플리케이션을 개발할 때 테스트까지 거친 튼튼한 데이터베이스 스키마로 시작하는가?
아니면, 특정 머신용으로 만들어진 스키마 위에서 불안한 토대를 바탕으로 애플리케이션을 구축하는가?
이 글에서는 고품질 애플리케이션을 만드는 데 꼭 필요한 데이터베이스 스키마 디자인을 살펴보기로 한다. 필자의 일상적인 개발 워크플로우를 소개하면서 도움이 될 몇 가지 팁을 알려주겠다. 애플리케이션은 계속 변하지만, 데이터는 영원하다는 점을 항상 염두에 두기 바란다.
객체지향 개발이 최선이 아닐 수도...
애플리케이션 개발자들에게 객체지향 기술은 매우 편리하지만, 데이터 관리 측면에서는 몇 가지 단점도 있다. 객체의 세계에서 데이터는 단순히 객체 상태(object state)로 간주된다. 따라서, 이 객체 상태를 이용해 적절한 객체 행동(object behavior)을 구현해야 한다. 훌륭한 객체 설계는 이 객체 상태를 인터페이스(일련의 메소드 호출) 뒤에 감추거나 캡슐화하는 것이다.
오늘날의 객체/관계 프레임워크 - 객체 상태를 관련 테이블로 매핑하는 - 덕분에 객체지향 개발자들은 관계형 데이터베이스를 직접 설계하거나 SQL 문을 작성하지 않아도 되며, 또는 선택한 데이터 스토어의 능력이나 성능 특징을 파악하지 않아도 된다. Java 2 Platform, Enterprise Edition(J2EE) 같은 프레임워크는 객체 상태를 지속시키는 데 적합한 데이터베이스 스키마를 만들어 낼 수 있다.
그리고, 데이터베이스 로우의 삽입, 업데이트, 삭제 및 질의를 위한 SQL 문이 자동으로 만들어진다. 하지만, 이것이 마냥 좋기만 한 것일까? 데이터 모델링과 관계 충실도 (relational fidelity), 직접 작성한 SQL 그리고 특정 벤더의 데이터베이스 기능을 포기할 때, 그것들과 함께 잃게 되는 것은 없을까?
모델을 만들지 말라
특정 머신용으로 만들어진 스키마는 훌륭한 데이터 모델러에 의해 만들어진 섬세한 디자인에 맞지 않는다. 비즈니스 영역의 데이터 요구사항을 파악하고 있는 데이터 모델러는 특정 애플리케이션에 얽매이지 않는 스키마를 만든다. 좋은 스키마는 다양한 유형의 비즈니스 문제들을 해결하기 위해 또 시간에 따른 환경 변화를 이겨내기 위해 특정 애플리케이션 구조를 추상화시킨다<그림 1>.
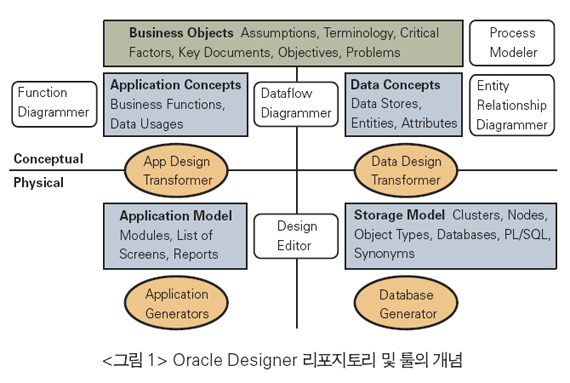
Tom Kyte(asktom.oracle.com)는 “애플리케이션 개발자는 애플리케이션이 데이터를 소유하지 않고, 단지 잠시 ‘빌리도록’ 해야 합니다. 그들이 개발한 애플리케이션은 살아남지 못할 가능성이 많지만, 데이터는 영원히 살아남을 것이고, 이후에 다른 애플리케이션이 그 데이터를 필요로 할것이라는 점을 염두에 두어야 합니다.”라고 말한다. 자신만의 SQL, 자신만의 데이터베이스 다수의 영속 프레임워크는 실행되는SQL을 거의 제어하지 못한다. 따라서, 원하는 결과를 정확하게 얻기 위해 SQL을 튜닝해 표현하는 데 한계가 있다. 데이터베이스는 매우 효율적으로 결과를 제공할 수 있지만, 최적의 SQL을 통해 원하는 것을 정확하게 알려줄 때만 그렇다.
또 다른 문제는, 애플리케이션은 종종 프레임워크가 생성할 수 있는 것보다 복잡한 쿼리를 필요로 한다는 것이다. 일례로, 계층적인 태스크 리스트에서 비용을 롤업하는 쿼리를 들 수 있다. 따라서, 쿼리에 사용되는 SQL을 오버라이드할 수 있는 Oracle Business Components for Java 같은 프레임워크를 선택하는 것이 좋다. SQL을 제어할 수 있는 또 다른 방법은 모든 SQL을 데이터베이스 저장 프로시저로 캡슐화해서 베이스 테이블 대신 뷰 사용을 최대한 늘리는 것이다.
일반적인 스키마는 관계형 데이터베이스 기능을 지능적으로 사용하는데 한계가 있어, 성능에 큰 영향을 미칠 수 있다. 데이터베이스는 결과를 제공하는 데 매우 효과적일 수 있지만, 옵션을 줄 때만 최적의 결과를 제공할 것이다. 관계 조인, 뷰, 집합, 서브쿼리, CONNECT BY, 아우터 조인 등은 비용기반 최적화기(CBO)에 매우 유용할 수 있지만, 일반적으로 영속 프레임워크에서는 무시되고 있는 것이다.
일반 스키마에서 특정 벤더의 데이터베이스 기능을 사용하는 일은 거의없다. 대다수 프레임워크에서는 수학, 스트링 핸들링, 보안, 외부 프로세싱, 공간/시간 계산, 통계와 분석을 위해 특별히 개발된 기능들을 활용하지 않는다. 데이터베이스의 이런 기능들을 활용하지 않으면, 결국 더 많은 코드를 추가하거나 비용이 많은 드는 개발, 유지관리 작업이 부대로 추가될것이다.
Oracle Designer로 모델링
기본 스키마를 형성할 수 있는 툴들이 많이 있지만, 개발자로서 필자는 오라클 데이터베이스 구조를 가장 잘 지원하는 Oracle Designer를 사용하고 있다. 이 Oracle Designer를 사용해 필자는 뷰, 객체 타입, 시퀀스, 체크 제약, 사용자와 역할, 데이터베이스 트리거, 저장 프로시저 등을 포함하는 완벽한 오라클 스키마를 구축할 수 있다. Oracle Designer는 다이어그램을 만들 수 있는 툴, 모델 변형기, 코드 생성기를 모두 포함하고 있으며, 이것들은 모두 상당히 포괄적인 리포지토리를 다루고 있다. 리포지토리에는 약 50여 개의 다른 객체 타입이 있다. <그림 1>은 디자인 툴들을 여러 범주로 나눠 정리한 것이다. Oracle Designer는 리포지토리를 개념적인 객체와 물리적 객체로 분류한다. 개념적인 객체(<그림 1>에서 상단 부분)는 비즈니스 모델을 캡처 하고, 요구사항을 분류하며, 애플리케이션을 설계하는 데 유용하다. 물리적 객체(<그림 1>에서 하단 부분)는 상세한 정보를 많이 가지고 있으며, 실제 코드와 데이터베이스 스키마 객체를 생성하는 데 사용된다.
필자는 새 애플리케이션을 개발할 때 주로 엔티티 관계 다이어그램(ERD)을 만드는 것부터 시작한다. 엔티티는 데이터 구조를 개념화한 것으로, 개발자가 데이터 - 그리고 데이터 간의 관계 - 에 대해 사고할 수 있도록 해주는데, 이것은 나중에 애플리케이션이 로우와 칼럼에서 데이터를 어떻게 명시할지 생각하지 않고 쉽게 데이터를 다룰 수 있도록 해준다. 이 시점에서 모든 속성을 구축할 필요는 없으며, 기본/외래 키를 포함하지 않아도된다. ERD는 또한 비즈니스 사용자들과의 추상적 토론을 전개하는 데도 매우 유용하다.
어느 시점에서든 Data Design Transformer를 실행시켜 미리 정해진 칼럼명과 인덱스, 기본/외래 키에 부합되는 데이터베이스 테이블 세트를 생성할 수 있다. 수퍼타입 또는 서브타입, 다대다 관계 등을 구축하면, Data Design Transformer가 이 구성체를 적절한 관계 테이블 구조 속으로 융합시켜 줄 것이다. 무엇보다, 이것은 일회성 오퍼레이션에 그치지 않고, 모델을 업데이트할 때마다 Data Design Transformer를 재실행시킬 수 있다. 또 무슨 작업이 진행되는지 항상 보여주고, 그 제안 내용을 미리 바꿈으로써 나중에 스키마에서 행해진 작업들을 파기하지 않도록 해준다.
그 다음, Design Editor를 사용해 스키마를 구축한다. 테이블 간의 관계는 ERD에서 이미 구축했으므로, 여기서는 상세 부분들을 정리한다. (Oracle Design Editor를 사용해 스토리지 모델을 만들고 데이터베이스 스키마를 생성한다면, 다른 개발 프로젝트 때보다 훨씬 나은 토대 위에서 작업을 진행할 수 있다.) 다음은 몇 가지 팁이다.
● 각 테이블과 칼럼에 주석을 입력하라. 이 주석들이 데이터베이스가 되어, 애플리케이션의 도움말 텍스트로 이용할 수 있다. 그 테이블이나 칼럼이 실제로 뭘 의미하는지서술하라(예를들어, 수치단위). 특히, NULL 값이 뭘의미 하는지 명시하도록 한다.
● 도메인은 칼럼 파라미터들의 세트로, 이름이 부여되어 있다. 도메인을 사용해 일관성, 특히 기본/외래 키 칼럼의 일관성을 유지하도록 한다.
● 칼럼이 추상적인 코드 값으로 되어 있다면, Allowable Values 대화상자에 전체 내용을 기술한다. Oracle Designer는 모든 코드 값을 포함하고 있는 테이블을 만들어 줄 것이므로, 이것을 팝업 리스트나 도움말의 텍스트로 쓸 수있다.
● 칼럼에 값의 범위가 정해져 있다면, Allowable Values에 그 범위를 입력하고 Hard Code를 선택하면, Oracle Designer가 체크 조건을 자동으로 만들어 낼 것이다.
● 기본 키 값의 경우, 데이터베이스가 SYS_GUID()의 디폴트 값을 사용해 기본 키 값을 정렬하도록 한다. 이렇게 하면, 테이블 내에서, 테이블 간에, 심지어 다른 데이터베이스에서도 기본 키가 동일하게 된다. 분산 시스템을 만들 때 특히 중요한 단계이다.
워크플로우
모델링 작업이 끝나고 나면, Oracle Designer 모델을 데이터베이스 스키마로 바꾸어야 한다. Oracle Designer에서 데이터베이스 모델은 매우 완벽해서 워크플로우에서 ‘가장 믿을 수 있는 것’으로 활용할 수 있다. Oracle Designer는 실제 DDL(Data Definition Language)을 생성하는데, 이것을 소스 제어 시스템에 저장한다. 또, Oracle Designer를 사용해 개발중인 데이터베이스에 바로 그 스키마를 전개할 수도 있다. Oracle Designer의 뛰어난 특징 중 하나는 타겟 데이터베이스 스키마와 모델을 비교해, 스키마와 모델의 일치를 위해 DDL을 어떻게 수정해야 할지 보여주는 것이다. 따라서, 필자는 Oracle Designer에서 제일 먼저 스키마에서 어떤 부분을 수정해야 할지 확인하고 수정한다. 그 다음 이 수정사항을 개발중인 데이터베이스에도 적용하고, 다른 시스템에서의 패치를 위해 SQL 스크립트를 확보해 둔다.
테스트
필자가 개발한 스키마를 데이터베이스에 전개해 실행시킨 다음, 테스트해 본 후 개발자들에게 사용법을 보여준다.
● 운에 맡겨두기보다는 공통 트랜잭션이나 여러 단계를 거쳐야 하는 트랜잭션을 위해 PL/SQL 저장 프로시저를 작성한다.
● 스키마의 기능과 성능을 테스트하기 위해 간단한 예제 질의를 작성한다. 가능한 한 개발자들이 스키마 사용법을 더 잘 파악할 수 있도록 데이터를 만든다.
● 데이터 무결성을 체크하고, 각각의 데이터 무결성 메커니즘을 체크하기 위한 테스트 스크립트를 작성한다.
● 보안 측면에서도 검토해 보고, 보안 관련 테스트 스크립트도 작성한다.
성과
끝으로, 모든 J2EE 프로젝트는 반드시 탄탄한 데이터베이스 스키마로 시작할 것을 권한다. 컨테이너 관리형 영속 프레임워크나 객체관계형 프레임워크가 데이터베이스를 ‘비트 버킷’으로 사용하도록 하면, 성능 저하로 이어질 수 있고, 미들 티어와 클라이언트 티어에서 더 많은 코드를 작성해야 할 것이며, 따라서 시장출하 시기도 늦춰지게 된다. 멋진 데이터베이스 스키마를 활용하지 않을 이유가 뭐란 말인가?
출처 : 오라클사
오라클 테크놀러지스트
애플리케이션을 개발할 때 테스트까지 거친 튼튼한 데이터베이스 스키마로 시작하는가?
아니면, 특정 머신용으로 만들어진 스키마 위에서 불안한 토대를 바탕으로 애플리케이션을 구축하는가?
이 글에서는 고품질 애플리케이션을 만드는 데 꼭 필요한 데이터베이스 스키마 디자인을 살펴보기로 한다. 필자의 일상적인 개발 워크플로우를 소개하면서 도움이 될 몇 가지 팁을 알려주겠다. 애플리케이션은 계속 변하지만, 데이터는 영원하다는 점을 항상 염두에 두기 바란다.
객체지향 개발이 최선이 아닐 수도...
애플리케이션 개발자들에게 객체지향 기술은 매우 편리하지만, 데이터 관리 측면에서는 몇 가지 단점도 있다. 객체의 세계에서 데이터는 단순히 객체 상태(object state)로 간주된다. 따라서, 이 객체 상태를 이용해 적절한 객체 행동(object behavior)을 구현해야 한다. 훌륭한 객체 설계는 이 객체 상태를 인터페이스(일련의 메소드 호출) 뒤에 감추거나 캡슐화하는 것이다.
오늘날의 객체/관계 프레임워크 - 객체 상태를 관련 테이블로 매핑하는 - 덕분에 객체지향 개발자들은 관계형 데이터베이스를 직접 설계하거나 SQL 문을 작성하지 않아도 되며, 또는 선택한 데이터 스토어의 능력이나 성능 특징을 파악하지 않아도 된다. Java 2 Platform, Enterprise Edition(J2EE) 같은 프레임워크는 객체 상태를 지속시키는 데 적합한 데이터베이스 스키마를 만들어 낼 수 있다.
그리고, 데이터베이스 로우의 삽입, 업데이트, 삭제 및 질의를 위한 SQL 문이 자동으로 만들어진다. 하지만, 이것이 마냥 좋기만 한 것일까? 데이터 모델링과 관계 충실도 (relational fidelity), 직접 작성한 SQL 그리고 특정 벤더의 데이터베이스 기능을 포기할 때, 그것들과 함께 잃게 되는 것은 없을까?
모델을 만들지 말라
특정 머신용으로 만들어진 스키마는 훌륭한 데이터 모델러에 의해 만들어진 섬세한 디자인에 맞지 않는다. 비즈니스 영역의 데이터 요구사항을 파악하고 있는 데이터 모델러는 특정 애플리케이션에 얽매이지 않는 스키마를 만든다. 좋은 스키마는 다양한 유형의 비즈니스 문제들을 해결하기 위해 또 시간에 따른 환경 변화를 이겨내기 위해 특정 애플리케이션 구조를 추상화시킨다<그림 1>.
Tom Kyte(asktom.oracle.com)는 “애플리케이션 개발자는 애플리케이션이 데이터를 소유하지 않고, 단지 잠시 ‘빌리도록’ 해야 합니다. 그들이 개발한 애플리케이션은 살아남지 못할 가능성이 많지만, 데이터는 영원히 살아남을 것이고, 이후에 다른 애플리케이션이 그 데이터를 필요로 할것이라는 점을 염두에 두어야 합니다.”라고 말한다. 자신만의 SQL, 자신만의 데이터베이스 다수의 영속 프레임워크는 실행되는SQL을 거의 제어하지 못한다. 따라서, 원하는 결과를 정확하게 얻기 위해 SQL을 튜닝해 표현하는 데 한계가 있다. 데이터베이스는 매우 효율적으로 결과를 제공할 수 있지만, 최적의 SQL을 통해 원하는 것을 정확하게 알려줄 때만 그렇다.
또 다른 문제는, 애플리케이션은 종종 프레임워크가 생성할 수 있는 것보다 복잡한 쿼리를 필요로 한다는 것이다. 일례로, 계층적인 태스크 리스트에서 비용을 롤업하는 쿼리를 들 수 있다. 따라서, 쿼리에 사용되는 SQL을 오버라이드할 수 있는 Oracle Business Components for Java 같은 프레임워크를 선택하는 것이 좋다. SQL을 제어할 수 있는 또 다른 방법은 모든 SQL을 데이터베이스 저장 프로시저로 캡슐화해서 베이스 테이블 대신 뷰 사용을 최대한 늘리는 것이다.
일반적인 스키마는 관계형 데이터베이스 기능을 지능적으로 사용하는데 한계가 있어, 성능에 큰 영향을 미칠 수 있다. 데이터베이스는 결과를 제공하는 데 매우 효과적일 수 있지만, 옵션을 줄 때만 최적의 결과를 제공할 것이다. 관계 조인, 뷰, 집합, 서브쿼리, CONNECT BY, 아우터 조인 등은 비용기반 최적화기(CBO)에 매우 유용할 수 있지만, 일반적으로 영속 프레임워크에서는 무시되고 있는 것이다.
일반 스키마에서 특정 벤더의 데이터베이스 기능을 사용하는 일은 거의없다. 대다수 프레임워크에서는 수학, 스트링 핸들링, 보안, 외부 프로세싱, 공간/시간 계산, 통계와 분석을 위해 특별히 개발된 기능들을 활용하지 않는다. 데이터베이스의 이런 기능들을 활용하지 않으면, 결국 더 많은 코드를 추가하거나 비용이 많은 드는 개발, 유지관리 작업이 부대로 추가될것이다.
Oracle Designer로 모델링
기본 스키마를 형성할 수 있는 툴들이 많이 있지만, 개발자로서 필자는 오라클 데이터베이스 구조를 가장 잘 지원하는 Oracle Designer를 사용하고 있다. 이 Oracle Designer를 사용해 필자는 뷰, 객체 타입, 시퀀스, 체크 제약, 사용자와 역할, 데이터베이스 트리거, 저장 프로시저 등을 포함하는 완벽한 오라클 스키마를 구축할 수 있다. Oracle Designer는 다이어그램을 만들 수 있는 툴, 모델 변형기, 코드 생성기를 모두 포함하고 있으며, 이것들은 모두 상당히 포괄적인 리포지토리를 다루고 있다. 리포지토리에는 약 50여 개의 다른 객체 타입이 있다. <그림 1>은 디자인 툴들을 여러 범주로 나눠 정리한 것이다. Oracle Designer는 리포지토리를 개념적인 객체와 물리적 객체로 분류한다. 개념적인 객체(<그림 1>에서 상단 부분)는 비즈니스 모델을 캡처 하고, 요구사항을 분류하며, 애플리케이션을 설계하는 데 유용하다. 물리적 객체(<그림 1>에서 하단 부분)는 상세한 정보를 많이 가지고 있으며, 실제 코드와 데이터베이스 스키마 객체를 생성하는 데 사용된다.
필자는 새 애플리케이션을 개발할 때 주로 엔티티 관계 다이어그램(ERD)을 만드는 것부터 시작한다. 엔티티는 데이터 구조를 개념화한 것으로, 개발자가 데이터 - 그리고 데이터 간의 관계 - 에 대해 사고할 수 있도록 해주는데, 이것은 나중에 애플리케이션이 로우와 칼럼에서 데이터를 어떻게 명시할지 생각하지 않고 쉽게 데이터를 다룰 수 있도록 해준다. 이 시점에서 모든 속성을 구축할 필요는 없으며, 기본/외래 키를 포함하지 않아도된다. ERD는 또한 비즈니스 사용자들과의 추상적 토론을 전개하는 데도 매우 유용하다.
어느 시점에서든 Data Design Transformer를 실행시켜 미리 정해진 칼럼명과 인덱스, 기본/외래 키에 부합되는 데이터베이스 테이블 세트를 생성할 수 있다. 수퍼타입 또는 서브타입, 다대다 관계 등을 구축하면, Data Design Transformer가 이 구성체를 적절한 관계 테이블 구조 속으로 융합시켜 줄 것이다. 무엇보다, 이것은 일회성 오퍼레이션에 그치지 않고, 모델을 업데이트할 때마다 Data Design Transformer를 재실행시킬 수 있다. 또 무슨 작업이 진행되는지 항상 보여주고, 그 제안 내용을 미리 바꿈으로써 나중에 스키마에서 행해진 작업들을 파기하지 않도록 해준다.
그 다음, Design Editor를 사용해 스키마를 구축한다. 테이블 간의 관계는 ERD에서 이미 구축했으므로, 여기서는 상세 부분들을 정리한다. (Oracle Design Editor를 사용해 스토리지 모델을 만들고 데이터베이스 스키마를 생성한다면, 다른 개발 프로젝트 때보다 훨씬 나은 토대 위에서 작업을 진행할 수 있다.) 다음은 몇 가지 팁이다.
● 각 테이블과 칼럼에 주석을 입력하라. 이 주석들이 데이터베이스가 되어, 애플리케이션의 도움말 텍스트로 이용할 수 있다. 그 테이블이나 칼럼이 실제로 뭘 의미하는지서술하라(예를들어, 수치단위). 특히, NULL 값이 뭘의미 하는지 명시하도록 한다.
● 도메인은 칼럼 파라미터들의 세트로, 이름이 부여되어 있다. 도메인을 사용해 일관성, 특히 기본/외래 키 칼럼의 일관성을 유지하도록 한다.
● 칼럼이 추상적인 코드 값으로 되어 있다면, Allowable Values 대화상자에 전체 내용을 기술한다. Oracle Designer는 모든 코드 값을 포함하고 있는 테이블을 만들어 줄 것이므로, 이것을 팝업 리스트나 도움말의 텍스트로 쓸 수있다.
● 칼럼에 값의 범위가 정해져 있다면, Allowable Values에 그 범위를 입력하고 Hard Code를 선택하면, Oracle Designer가 체크 조건을 자동으로 만들어 낼 것이다.
● 기본 키 값의 경우, 데이터베이스가 SYS_GUID()의 디폴트 값을 사용해 기본 키 값을 정렬하도록 한다. 이렇게 하면, 테이블 내에서, 테이블 간에, 심지어 다른 데이터베이스에서도 기본 키가 동일하게 된다. 분산 시스템을 만들 때 특히 중요한 단계이다.
워크플로우
모델링 작업이 끝나고 나면, Oracle Designer 모델을 데이터베이스 스키마로 바꾸어야 한다. Oracle Designer에서 데이터베이스 모델은 매우 완벽해서 워크플로우에서 ‘가장 믿을 수 있는 것’으로 활용할 수 있다. Oracle Designer는 실제 DDL(Data Definition Language)을 생성하는데, 이것을 소스 제어 시스템에 저장한다. 또, Oracle Designer를 사용해 개발중인 데이터베이스에 바로 그 스키마를 전개할 수도 있다. Oracle Designer의 뛰어난 특징 중 하나는 타겟 데이터베이스 스키마와 모델을 비교해, 스키마와 모델의 일치를 위해 DDL을 어떻게 수정해야 할지 보여주는 것이다. 따라서, 필자는 Oracle Designer에서 제일 먼저 스키마에서 어떤 부분을 수정해야 할지 확인하고 수정한다. 그 다음 이 수정사항을 개발중인 데이터베이스에도 적용하고, 다른 시스템에서의 패치를 위해 SQL 스크립트를 확보해 둔다.
테스트
필자가 개발한 스키마를 데이터베이스에 전개해 실행시킨 다음, 테스트해 본 후 개발자들에게 사용법을 보여준다.
● 운에 맡겨두기보다는 공통 트랜잭션이나 여러 단계를 거쳐야 하는 트랜잭션을 위해 PL/SQL 저장 프로시저를 작성한다.
● 스키마의 기능과 성능을 테스트하기 위해 간단한 예제 질의를 작성한다. 가능한 한 개발자들이 스키마 사용법을 더 잘 파악할 수 있도록 데이터를 만든다.
● 데이터 무결성을 체크하고, 각각의 데이터 무결성 메커니즘을 체크하기 위한 테스트 스크립트를 작성한다.
● 보안 측면에서도 검토해 보고, 보안 관련 테스트 스크립트도 작성한다.
성과
끝으로, 모든 J2EE 프로젝트는 반드시 탄탄한 데이터베이스 스키마로 시작할 것을 권한다. 컨테이너 관리형 영속 프레임워크나 객체관계형 프레임워크가 데이터베이스를 ‘비트 버킷’으로 사용하도록 하면, 성능 저하로 이어질 수 있고, 미들 티어와 클라이언트 티어에서 더 많은 코드를 작성해야 할 것이며, 따라서 시장출하 시기도 늦춰지게 된다. 멋진 데이터베이스 스키마를 활용하지 않을 이유가 뭐란 말인가?
출처 : 오라클사
'DATABASE' 카테고리의 다른 글
| [ORACLE] rowid와 rownum의 정의와 사용법 (0) | 2011.10.16 |
|---|---|
| [ORACLE] lock 걸린 테이블 및 유저찾기 (0) | 2011.10.16 |
| [ORACLE] SP에서 테이블 생성 (0) | 2011.10.16 |
| [ORACLE] backup (exp/imp) (0) | 2011.10.16 |
| [ORACLE] 25가지 SQL작성법 (0) | 2011.10.16 |